
SMoLPU
My Contributions:
- Development of token adaptive expert refinement and a MoE PSUM management policy
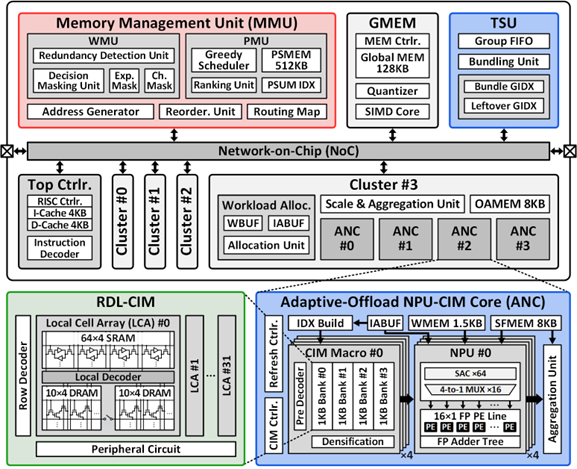
- Design of memory management unit
This work introduces SMoLPU, an energy-efficient MoE-based speculative decoding LLM processor with an NPU-CIM core. Each phase in sparse MoE-based speculative decoding LLM system has its own challenges. The decoding stage suffers from significant weight redundancy, caused by both unnecessary activation of experts for mis-predicted (and thus rejected) tokens and sparsity arising since the expert outputs are scaled by their routing score. In prefill stage, sequential loading of 4 MB experts requires PSUM caching to aggregate all expert outputs, which enlarges the PSUM footprint and further increases EMA. SMoLPU proposes Token adaptive Expert Refinement (TaER) with a weight management unit (WMU) and a PSUM management unit (PMU) that eliminate redundant expert fetching and reduce EMA.